作者|汤一涛
编辑|靖宇
Opus 4.7 刚发布那几天,X 上怨声载道。有人说一次对话就把她的 session 额度用光了,有人说同一段代码跑完的成本比上周翻了一倍多;还有人晒出自己 200 美元 Max 订阅不到两小时就触顶的截图。
独立开发者 BridgeMind 承认 Claude 是世界上最好的模型,但同时也是最贵的模型。他的 Max 订阅用不到两小时就限额了,但幸好——他买了两份。|图片来源:X@bridgemindai
Anthropic 官方价格没变,每百万输入 token 仍是 5 美元,输出 25 美元。但这个版本引入了新 tokenizer,同时 Claude Code 把默认 effort 从 high 提到了 xhigh。两件事叠加,同一份工作消耗的 token 变成了以前的 2 到 2.7 倍。
我在这些讨论里看到两个和中文有关的说法。一个是:中文在新 tokenizer 下几乎没涨,中文用户躲过了这次涨价。另一个更有意思:古文比现代汉语还省 token,用文言文跟 AI 对话可以节省成本。
第一个说法暗示 Claude 对中文做了某种优化,但 Anthropic 的发布文档里,没提过任何和中文相关的调整。
第二个说法则更难解释。古文对人类读者来说显然比现代汉语难懂,一个对人类更复杂的文本,怎么会对 AI 更容易?
于是我做了一次测试,用 22 段平行文本(包含商业新闻、技术文档、古文、日常对话等类型),同时送进 5 个 tokenizer(Claude 4.6 和 4.7、GPT-4o、Qwen 3.6、DeepSeek-V3),读取每段文本在每个模型下的 token 数,做横向对比。

测试文本:
1、日常对话中英文(旅行、论坛求助、写作请求)
2、技术文档中英文(python 文档、Anthropic 文档)
3、新闻中英文(NYT 时政新闻、NYT 商业新闻、苹果公司官方声明)
4、文学选段中英古汉语(《出师表》《道德经》)
测完之后,两个说法都得到了部分验证,但事实会比传言更复杂一些。
01
中文税
先说结论:
1、在 Claude 和 GPT 上,中文一直比英文贵
2、在 Qwen 和 DeepSeek 上,中文反而比英文便宜
3、Opus 4.7 这次引发震荡的 tokenizer 升级,通胀几乎只发生在英文上,中文纹丝不动
看具体数字。Claude Opus 4.7 之前的全系列模型(包括 Opus 4.6、Sonnet、Haiku),使用的是同一个 tokenizer。在这个 tokenizer 下,中文的 token 消耗全线高于等量英文内容,cn/en 比值范围在 1.11× 到 1.64× 之间。
最极端的场景出现在 NYT 风格的商业新闻:同一段内容,中文版要多消耗 64% 的 token,等于多付 64% 的钱。
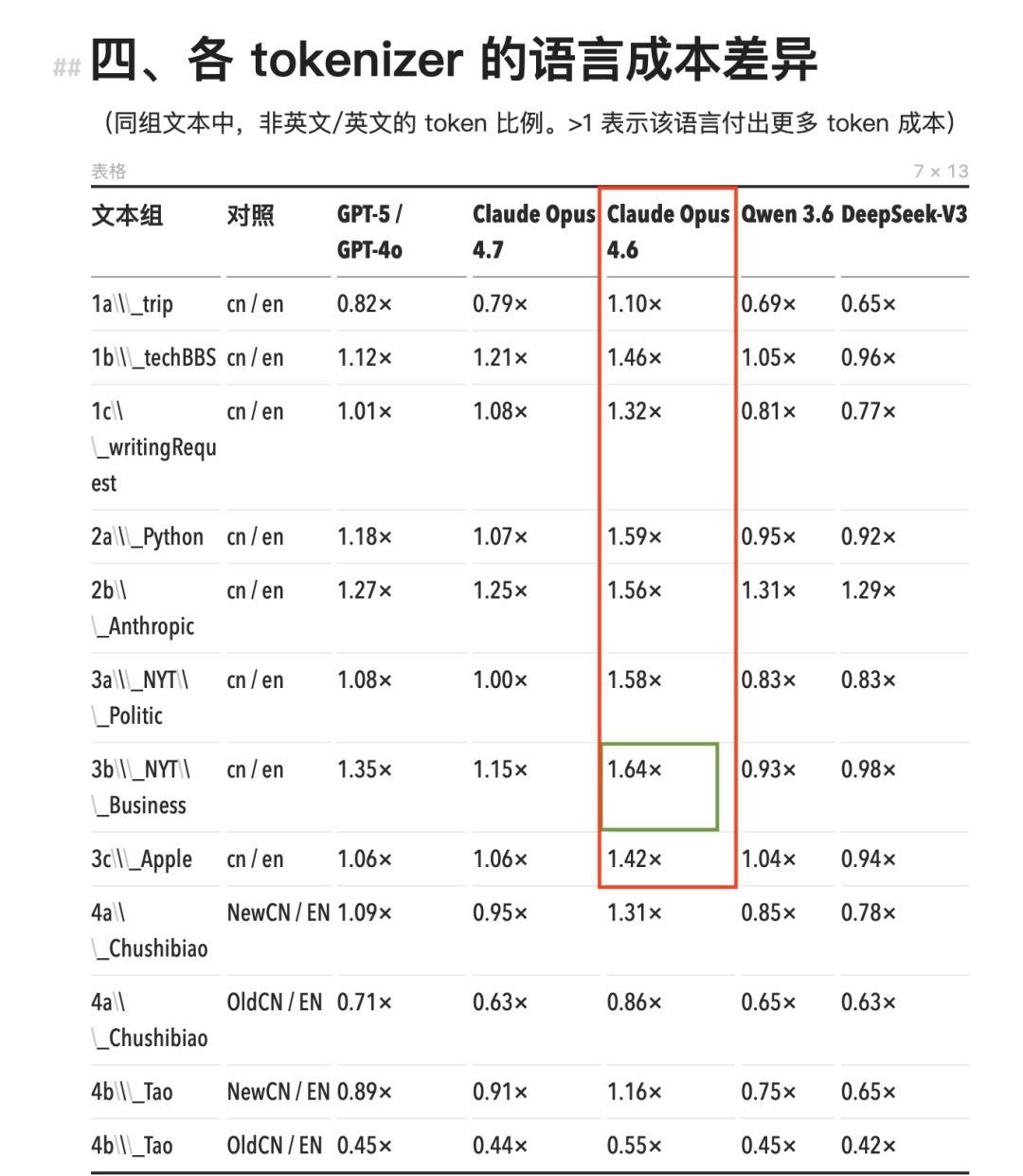
Opus 4.6 及其之前的 Claude 模型,中文 token 的消耗量显著高于其它模型(红框)
最极端的场景出现在 NYT 风格的商业新闻:同一段内容,中文版要多消耗 64% 的 token(绿框)
GPT-4o 的 o200k tokenizer 好一些,cn/en 比值多数落在 1.0 到 1.35× 之间,部分场景低于 1。中文仍然整体偏贵,但差距比 Claude 小得多。
国产模型 Qwen 3.6 和 DeepSeek-V3 的数据则完全反了过来。两者的 cn/en 比值大面积低于 1,这意味着同样的内容,中文版反而比英文版省 token。DeepSeek 最低做到了 0.65×,同一段话中文版比英文版便宜三分之一。
Opus 4.7 的新 tokenizer 通胀几乎只发生在英文上。英文 token 数膨胀了 1.24× 到 1.63×,中文大量维持在 1.000×,几乎没有变化。开头那些英文开发者的账单震荡,中文用户确实没感受到。原因可能是中文在旧版上已经被切到了单字颗粒度,可拆分的空间极小。
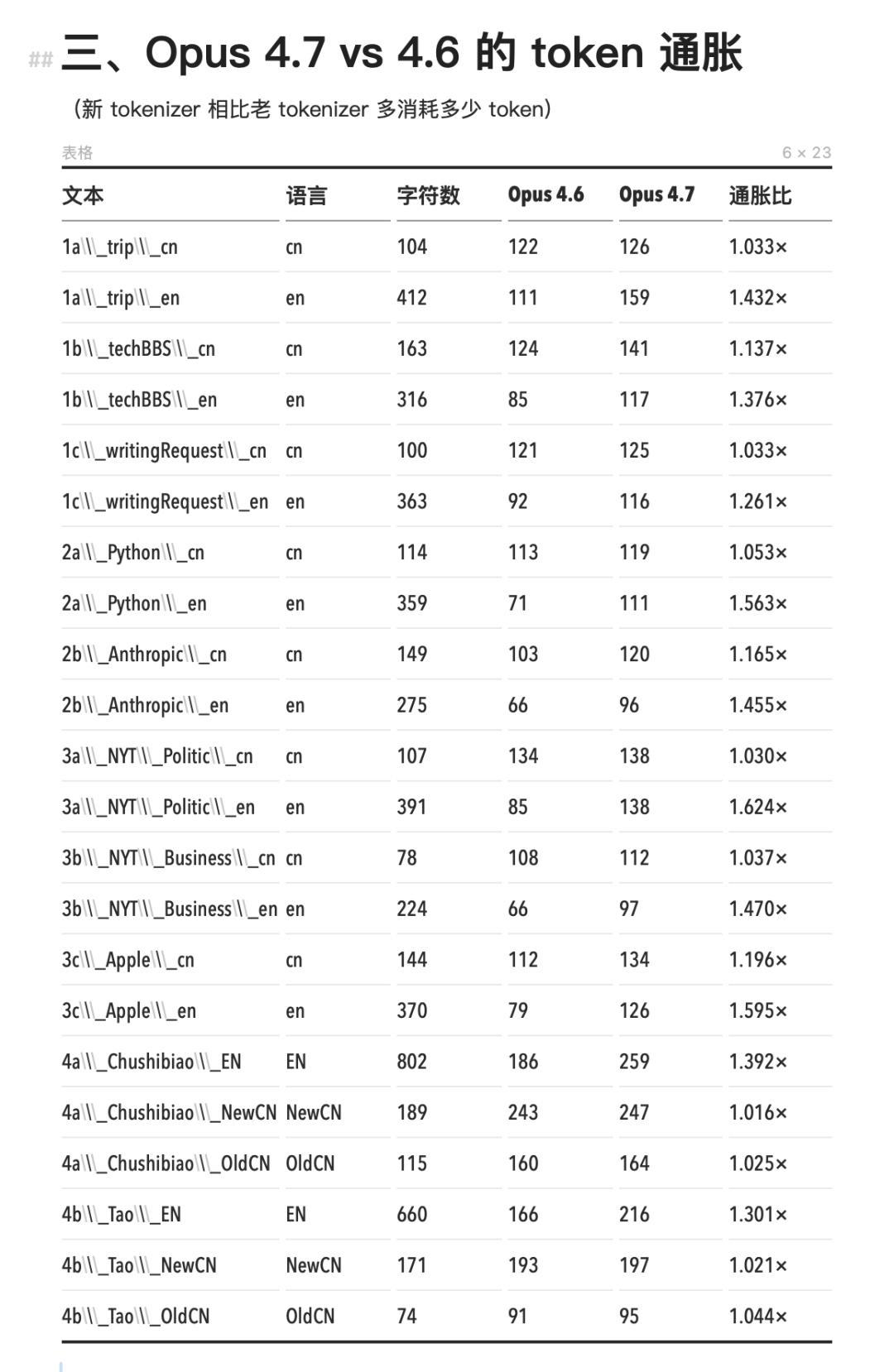
Opus 4.7 对比 4.6,英文消耗的 token 更多了,中文反而没变
测试过程中我还注意到一件事。token 消耗的差异不只是账单问题,它直接影响工作空间的大小。同样 200k 上下文窗口,用旧版 Claude tokenizer 装中文资料,能塞进去的内容量比英文少 40% 到 70%。
同一类工作,比如让 AI 分析一份长文档或者是总结一组会议记录,中文用户能喂给模型的材料更少,模型能参考的上下文更短。结果就是付了更多的钱,但得到的是更小的工作空间。
四组数据放在一起看,一个问题自然浮出来:
为什么同一段内容换个语言,token 数就不一样?为什么 Claude 和 GPT 的中文贵,Qwen 和 DeepSeek 的中文反而便宜?
答案藏在上文多次提到的概念 tokenizer(分词器)上。
02
一个汉字,可以切成几块?
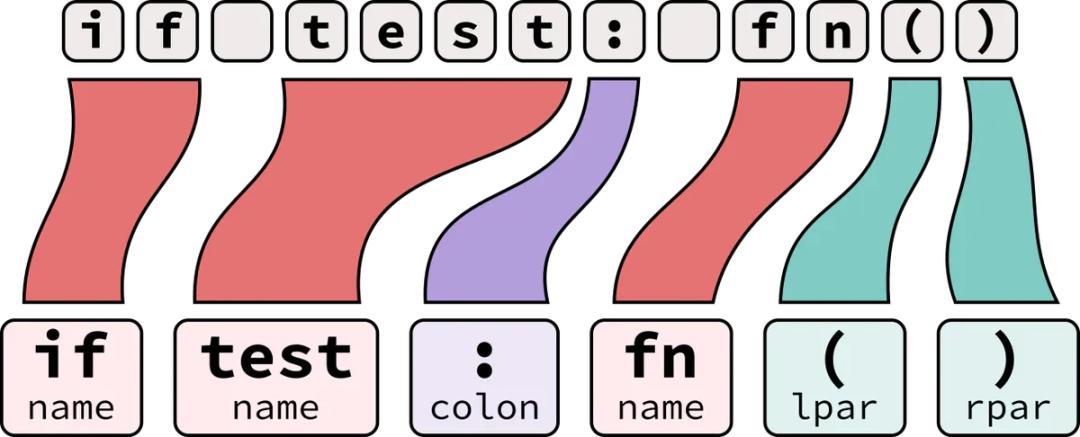
模型在读到任何文字之前,会通过 tokenizer 把输入切成一个个 token。你可以把 tokenizer 想象成 AI 的“积木切割机”。你输入一句话,它负责把这句话拆成一块块标准化的积木(也就是 token)。AI 模型不看文字,只认积木的编号。你用多少块积木,就付多少钱。
英文的切法比较符合直觉,比如“intelligence”大概率是一个 token,“information”也是一个 token,一个单词对应一个计费单位。

但中文到了这一步就出问题了。把同一句话“人工智能正在重塑全球的信息基础设施”分别送进 GPT-4 的 cl100k tokenizer 和 Qwen 2.5 的 tokenizer,切出来的结果完全不同。
GPT-4 基本把每一个汉字都拆成了一个 token;Qwen 则会把词语识别成一个 token,例如“人工智能”这 4 个字在千问只算一个 token。
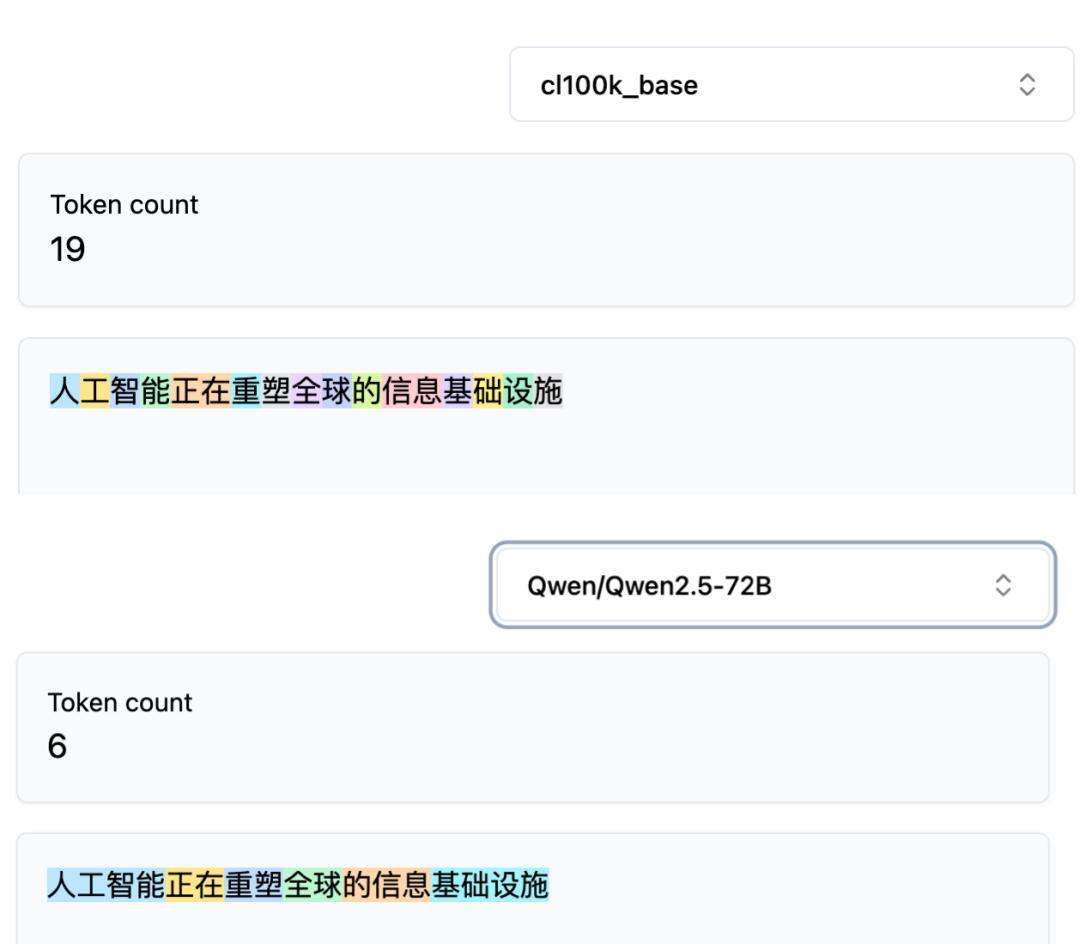
同一句 16 个汉字的话,GPT-4 切出来 19 个 token,Qwen 切出来只有 6 个。
为什么会切成这样?原因在一个叫 BPE(Byte Pair Encoding)的算法。
BPE 的工作方式,是统计训练语料里哪些字符组合出现频率最高,然后把高频组合合并成一个 token,纳入词表。
GPT-2 时代,训练语料的绝大多数是英文。英文字母组合(th、ing、tion)反复出现,很快就被合并成 token。中文字符在那个语料池里出现的频率太低,排不进词表,只能被当作原始字节来处理,一个汉字占 3 个字节,就变成了 3 个 token。
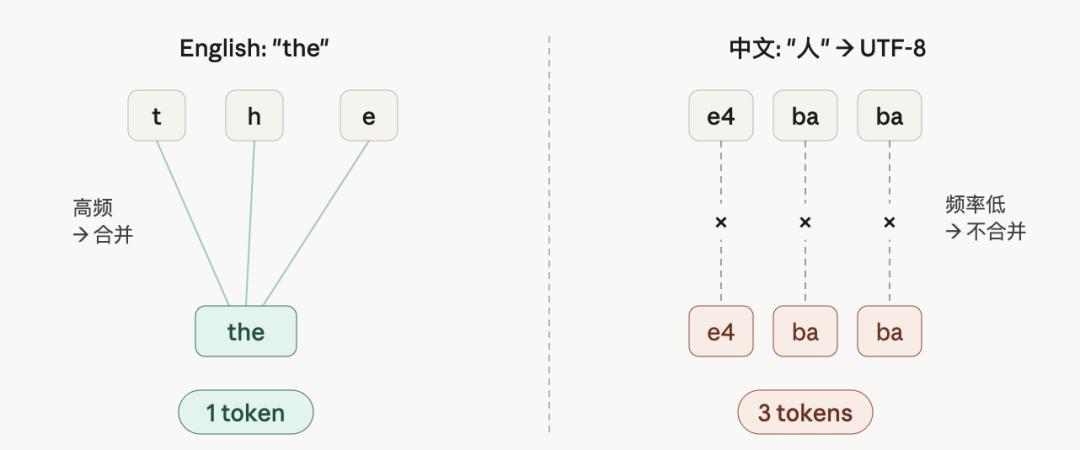
BPE 按训练语料中的字符频率决定合并。英文语料主导下,中文 UTF-8 字节无法合并为整字
后来 GPT-4 的 cl100k 词表扩大了,常用汉字开始被纳入,一个字通常缩到 1 到 2 个 token,但整体效率仍然不如英文。
到了 GPT-4o 的 o200k 词表,中文效率再进了一步。这也解释了为什么第一段的数据里 GPT-4o 的 cn/en 比值比 Claude 低。
Qwen 和 DeepSeek 作为国产模型,从一开始就把大量常用汉字和高频词组作为整字、整词纳入词表。一个字一个 token,效率直接翻倍甚至更多。

同一句话在不同 tokenizer 下的拆分结果示意图
这就是为什么它们的 cn/en 比值能低于 1,中文字均信息密度本来就高于英文单词,当 tokenizer 不再人为拆碎汉字,这个天然优势就显现出来了。
所以上一节那四组数据的差异,根源不在模型的能力,而在 tokenizer 的词表里,给中文留了多少位置。
Claude 和早期 GPT 的词表是以英文为默认值构建的,中文是后来被“塞进去”的;Qwen 和 DeepSeek 的词表从设计之初就把中文当作默认语言对待。这个起点的差异,一路传导到 token 数、账单、上下文窗口大小。
03
古文真的更便宜吗?
再看开头的第二个传言:古文比现代汉语更省 token。
数据确认了这个说法。在测试里,古文样本的 cn/en 比值全线低于 1,在所有五个 tokenizer 上都一致。同一段内容的古文版本,token 数比对应英文翻译还少。
在所有模型中,古文消耗的 token 数不但比现代中文少,甚至比英文还少
原因也不复杂,古文用字极度精炼。“学而不思则罔,思而不学则殆”是 12 个字。翻译成现代汉语就是“只是学习而不思考就会迷惑,只是思考而不学习就会陷入困境”,字数直接翻倍,token 数自然也跟着翻倍。
而且古文的常用字(之、也、者、而、不)都是高频字符,在任何 tokenizer 的词表里都有独立位置,不会被拆成字节。所以古文在编码层面确实是高效的。
但这里藏着一个陷阱。
古文的 token 省在编码端,但模型的推理负担没有减轻。“罔”一个字,模型需要判断它在这个语境里是“迷惑”“被蒙蔽”还是“没有”。现代汉语可以用 26 个字把这层意思说清楚,用古文等于把铺开的部分压了回去,把推理的活留给了模型。打个比方,一份压缩成 zip 的文件体积更小,但解压它需要更多计算。
token 省了,推理的消耗反而上升了,理解准确度还下降了。这笔账算不过来。
古文这个例子让我意识到,token 数量本身不能说明太多问题。但顺着这个方向想下去,还有一层我之前忽略了的东西。
上面说过,GPT-2 时代的 tokenizer 会把“人”这个字拆成三个 UTF-8 字节 token,后来 GPT-4 的词表扩大,常用汉字变成了一个字一个 token,Qwen 更进一步,把“人工智能”四个字合成一个 token。
直觉上这是一个不断改进的过程:合并得越多,效率越高,模型应该也理解得越好。
但真的是这样吗?我们不妨回忆一下,我们是如何认识汉字的。
汉字是表意文字,现代汉字里超过 80% 是形声字,由一个表义的偏旁和一个表音的部件组合而成。“氵”旁的字多和液体有关,“木”旁的字多和植物有关,“火”旁的字多和热量有关。偏旁部首就是人类识字时最基础的语义线索,一个不认识“焱”字的人,看到 3 个“火”也能猜到它和火有关。
因为偏旁部首是人类识字时最基础的语义线索,人会先从结构推断意义范畴,再结合语境理解具体含义。

火花、火焰、光焰,书面语与人名中多见,寓意光明、炽热。
但是在 tokenizer 的词表里,“焱”这个字对应的是一个编号。我们假设它是 38721 号,它代表的是词表里的一个索引位置,模型通过它查找到一组数字向量,用这组向量来表征“焱”这个字。
编号本身不携带任何关于这个字内部结构的信息。38721 和 38722 的关系,对模型来说和 1 和 10000 的关系没有区别。于是,“汉字的结构”这一层信息,就被封装起来了。三个“火”叠在一起这件事,在编号里不存在。
模型当然可以通过大量训练数据间接学到“焱”“炎”“灼”经常出现在相似的语境里,但这条路比直接利用偏旁信息要更间接一些。
所以模型能不能从拆开的字节里,“看到”某些类似偏旁的结构线索,然后在后续的计算层里重新组合呢?这条路虽然 token 数多、成本高,但有没有可能在语义理解上,反而比直接吞下一个不透明的编号更有效?
2025 年发表在 MIT Press《Computational Linguistics》上的一篇论文(《Tokenization Changes Meaning in Large Language Models: Evidence from Chinese》),回答了这个问题。
04
碎片里长出偏旁
论文作者 David Haslett 注意到一个历史巧合。
1990 年代,Unicode 联盟在给汉字分配 UTF-8 编码时,排列顺序是按部首归类排的。同一个部首下的汉字,UTF-8 编码是相邻的。“茶”和“茎”都含有“艹”部(草字头),它们的 UTF-8 字节序列以相同的字节开头。“河”和“海”都含有“氵”部,字节序列同样共享开头。
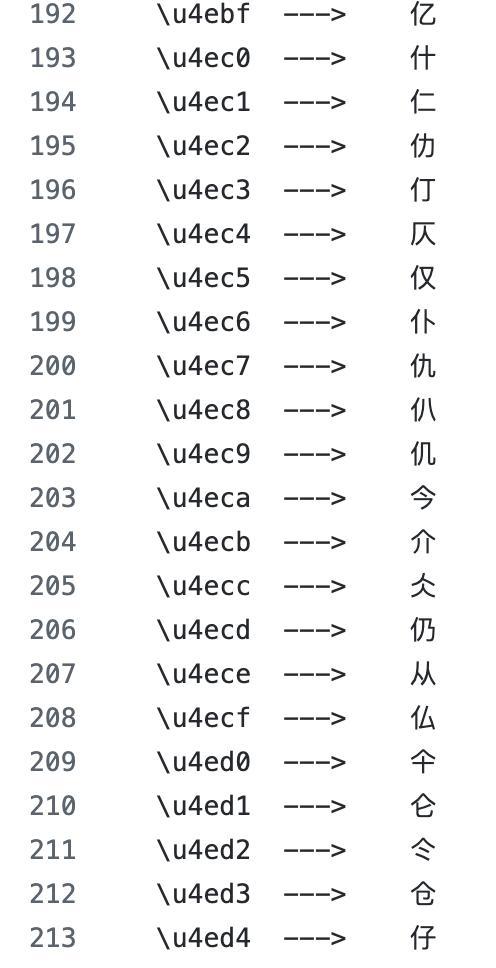
UTF-8 按照部分部首顺序给中文排序,部首相同的字,编码相近|图片来源:Github
这意味着,当 tokenizer 把汉字拆成三个 UTF-8 字节 token 的时候,共享部首的汉字会共享第一个 token。模型在训练过程中反复看到这些共享的字节模式,有可能从中学到“第一个 token 相同的字,往往属于同一个意义范畴”。这在功能上就接近于人类通过偏旁判断语义的过程。
Haslett 设计了三个实验来验证这件事。
第一个实验询问 GPT-4、GPT-4o 和 Llama 3:“茶”和“茎”是否含有相同的语义部首?
第二个实验让模型给两个汉字的语义相似度评分。
第三个实验让模型做“找出不同类”的排除任务。
每个实验都控制了两个变量:两个汉字是否真的共享部首、两个汉字在 tokenizer 下是否共享第一个 token。这个 2×2 的设计,让她能分离出部首效应和 token 效应各自的影响。
三个实验的结论一致:当汉字被切成多个 token 时(比如 GPT-4 的旧 tokenizer 下,89% 的汉字被切成了多 token),模型识别共享部首的准确率更高;当汉字被编码为单个 token 时(GPT-4o 的新 tokenizer 下,只有 57% 的汉字还是多 token),准确率下降了。
换句话说,上一段的那个猜想成立了。把汉字切碎,成本确实更高,但切碎后的字节序列里保留了部首的痕迹,模型真的从中学到了一些东西。而把汉字编码为整字 token,成本降下来了,但部首信息被封装在一个不透明的编号里,模型无法再通过字节序列获取这一线索。
需要特别说明的是,这一结论仅局限于字形相关的细分语义任务,不能等同于模型整体的中文理解、逻辑推理、长文本生成能力下降。同时,实验对比的 GPT-4 与 GPT-4o,除了分词器差异外,模型架构、训练语料、参数量均有显著变化,无法将准确率变化 100% 归因于分词粒度的调整。
这个发现还得到了工程侧的验证。2024 年一项针对 GPT-4o 的研究发现,GPT-4o 的新 tokenizer 把某些中文字符组合合成了一个长 token 之后,模型反而出现了理解错误。当研究者用专业的中文分词器,把这些长 token 重新拆开再喂给模型,理解准确度恢复了。
目前全球大模型行业的主流共识,依然是针对目标语言优化的整词 / 整字分词器,能显著提升模型的整体性能。整字 / 整词编码不仅能大幅降低 token 成本、提升上下文窗口的有效信息量,还能缩短序列长度、降低推理延迟、提升长文本处理的稳定性。论文中发现的细分任务优势,无法覆盖绝大多数中文 NLP 场景的性能收益。
但这件事依然戳中了大型系统里最难处理的一类问题:你能优化你设计过的部分,但你没法优化你不知道自己拥有的部分。Unicode 联盟按部首排列编码,是为了人类检索的方便。BPE 把汉字拆成字节,是因为中文在语料里的频率太低。两个不相关的工程决策碰巧叠在一起,产生了一条谁都没规划过的语义通道。
然后,当新一代工程师“改进”tokenizer、把汉字合并为整字 token 的时候,他们同时抹掉了一条自己不知道存在的路。效率提升了,成本降低了,某些东西也安静地消失了,而你甚至不会收到一条报错信息。
所以事情比“中文在 AI 里多付钱”这个判断更复杂。每一种 tokenizer 都在为某个默认值优化,代价藏在了别处。
05
林语堂
中文适配西方技术基础设施的代价,不是 AI 时代才开始付的。
2025 年 1 月,纽约居民 Nelson Felix 在 Facebook 一个打字机爱好者小组里发了几张照片。他在妻子祖父的遗物里发现了一台刻满中文的打字机,不知道是什么来历。很快数百条评论涌入。

Nelson Felix 的问题:明快打字机值钱吗?|图片来源:Facebook
斯坦福大学汉学家墨磊宁(Thomas S. Mullaney)看到照片后立刻认出来了,这是林语堂 1947 年发明的“明快打字机”的唯一原型机,失踪了将近 80 年。同年 4 月,Felix 夫妇将打字机卖给斯坦福大学图书馆。
明快打字机要解决的问题,和今天 tokenizer 面对的问题在结构上是同一个:怎么把中文高效地嵌入一套为西方语言设计的技术基础设施。
1940 年代的英文打字机有 26 个字母键,一键一字,简单直接。中文有几千个常用字,不可能一键一字。当时的中文打字机是一个巨大的字盘,排着几千个铅字,打字员用手逐个捡字,每分钟只能打十几个字。

1899年,美国传教士谢卫楼(Devello Z. Sheffield)所发明的中文打字机,是中文打字机最早的纪录|图片来源:Wikipedia
林语堂耗资 12 万美元研发经费,几乎倾家荡产,委托纽约的 Carl E. Krum 公司做出了一台只有 72 个键的中文打字机。工作原理是把汉字按字形结构拆开,上形键选字根上半部、下形键选字根下半部,候选字显示在一个叫“魔术眼”的小窗里,按数字键选中。每分钟 40 到 50 字,支持 8000 余常用字符。

(左)透明玻璃小窗即位“魔术眼”;(右)明快打字机内部结构|图片来源:Facebook
赵元任评价:“不论中国人还是美国人,只要稍加学习,便能熟悉这一键盘。我认为这就是我们所需要的打字机了。”
技术上明快打字机是一种突破,但商业上它失败了。
林语堂向雷明顿公司高管演示时机器出了故障,投资者随之失去兴趣,而造价高昂加上他个人资金链断裂,量产再无可能。1948 年,林语堂将原型机和商业权,卖给默根特勒铸排机公司(Mergenthaler Linotype)。该公司最终放弃量产,原型机在 1950 年代公司搬迁时被一位员工带回长岛家中,之后下落不明,直到 2025 年重见天日。
墨磊宁在《中文打字机》一书里有一个判断,他认为明快打字机“并不失败”。作为一款 1940 年代的产品,它确实失败了。但作为一种人机交互范式,它胜利了。
林语堂第一次把中文“打字”变成了“检索加选择”。三排按键组合定位字根,从候选字里挑选。这正是所有现代中文输入法的底层逻辑。从仓颉、五笔到搜狗拼音,都可以说是明快打字机的后裔。

《中文打字机》,作者:墨磊宁|图片来源:豆瓣
这台跨越了近八十年的打字机,和今天我们反复讨论的分词器,暗藏着某种的历史规律。中文始终面对着一个问题:
如何接入一套罗马字母形成的基础设施。
有趣的是,在这个寻找的过程中,充满了非人为规划的巧合。Unicode 联盟为了人类检索方便制定的排序,跟 BPE 算法的无心拆解叠在一起,竟然在神经网络的黑盒里,重现了人类识字的过程。而当工程师们为了消除“中文税”,主动把汉字拼好、把成本打下来时,那条意外诞生的语义通道也闭合了。
历史并不是一条直线进化的轨道,而是在各种约束条件的挤压下,不断发生变形的流体。
有些能力是设计出来的,有些只是碰巧没有被删掉。