
启用新协议,一级核心交换机可直接重启不影响模型训练。
芯东西5月7日消息,昨日晚间,OpenAI与AMD、博通、英特尔、微软、英伟达联合发布全新开放网络协议MRC(多路径可靠连接),可帮助大型AI训练集群更快、更可靠地运行。OpenAI通过开放计算项目(OCP)发布了MRC。
MRC已部署在OpenAI所有用于训练前沿模型的超级计算机上,包括位于美国德克萨斯州阿比林的美国甲骨文云基础设施(OCI)站点,以及微软Fairwater超级计算机等。
MRC是一种内置于最新800Gb/s网络接口中的新网络协议,可将单次数据传输分流至数百条路径、微秒级绕开故障链路,同时还能简化网络控制面架构。
OpenAI官方博客提到,近期为ChatGPT与Codex训练一款前沿大模型时,他们不得不重启四台一级核心交换机,以往重启交换机需运维团队极度谨慎,引入MRC之后,他们甚至无需与集群训练任务的运维团队提前协调就可重启。
在打造基建项目Stargate之前,OpenAI已与合作伙伴在几年间开发并维护了前三代超级计算机,这使其认识到要在超级计算机上高效利用算力并成功完成任务,需要大幅降低堆栈每一层的复杂性,包括重新设计网络。
OpenAI官方账号X的评论区有不少网友肯定了MRC的发布,称其是真正的基础设施进步、标志着基础设施竞争转向标准化集群通信效率时代。

01.
破解网络难题
MRC对扩展超级计算机有三大助力
训练大模型时,一个步骤可能涉及数百万次数据传输,而一次延迟传输可能会在整个作业中波动导致GPU处于空闲状态,而网络拥塞、链路和设备故障是传输延迟和抖动最常见的原因。
随着算力基建规模的增大,这些问题发生得更频繁且更难解决。其面临两个关键的网络挑战:要尽可能降低网络拥塞的发生概率,尽量减少网络故障对训练工作本身的影响。
基于此,OpenAI联合多家芯片公司打造了MRC。其目标是打造一个即使在出现故障时也能提供高度可预测性能的网络,以保持训练任务能持续推进。
MRC是对聚合以太网RDMA(RoCE)的扩展。RoCE是由无限带宽行业协会制定的标准,能够在GPU与CPU之间实现硬件加速的远程直接内存访问。MRC借鉴了超以太网联盟(UEC)研发的技术,并基于SRv6源路由对其进行能力扩展,从而支撑大规模AI网络架构组网。
该网络架构已依托英伟达和博通的硬件,支撑多款OpenAI模型训练。
AMD为MRC贡献了拥塞控制技术,以提升MRC的实际性能,且AMD已经与头部云服务商合作,在测试集群中大规模部署MRC,在MRC规范开发之前,AMD已有改进版RoCEv2传输协议的预标准实现,该协议演变为今日的MRC标准。AMD的官方新闻稿提到,其是最早且唯一在400G网卡上实现MRC的公司之一,他们可以无缝过渡到AMD Pensando“Vulcano”800G AI NIC的应用,该NIC同样支持MRC传输协议。
MRC是首次在英伟达Spectrum-X以太网上验证并优化的新传输协议,其故障绕过技术可以在仅几微秒内检测网络路径故障,并在硬件中自动重路由流量。英伟达官方博客提到,这种绕过失败技术对于AI训练集群尤为重要,因为成千上万的GPU必须保持同步,即使是短暂的网络中断也可能减缓甚至中断整个训练任务。
博通Thor Ultra是一款面向AI负载与多平面架构网络设计的800Gbps高性能以太网卡。该产品基于数代RoCE网卡技术打造,新增支持MRC以及高级RoCE技术。博通官方博客称,其将这项技术与经验投入到了MRC生态合作研发当中。Thor Ultra集成了使用网络编程语言(NPL)实现高带宽线率可编程数据路径,实现先进拥塞控制(基于发送端和接收端)、负载均衡以及可靠传输等功能,可以降低系统成本和复杂度。
英特尔在官方X账号发帖称,借助MRC技术,英特尔正构建多平面以太网组网架构,该架构可实现超大规模集群部署,同时减少交换机层级、降低功耗、提升整体可靠性。
MRC为其扩展超级计算机带来三个关键优势:
首先,该技术仅通过两层以太网交换机,就能搭建出可承载十万块GPU规模超算的多平面高速网络。这套架构具备充足冗余能力,可平稳抵御网络故障;同时相比同等规模的三层、四层单平面网络,功耗更低。
其次,MRC的自适应数据包散射具备极佳的负载均衡能力,使得网络核心基本不会出现拥塞。
这降低了同步训练中各数据流之间的吞吐量波动,而消除异常延迟正是同步训练性能优化的核心关键。同时,即便多项任务共享同一个超算集群,彼此之间也不会产生性能干扰。
最后,MRC采用SRv6源路由快速绕过故障链路,仅在正常可用路径上转发数据包。
这使得其可以采用简洁的静态网络控制面,并从根本上规避一大类动态路由特有的故障异常问题。
02.
支持多平面网络
可实现更低成本、功耗
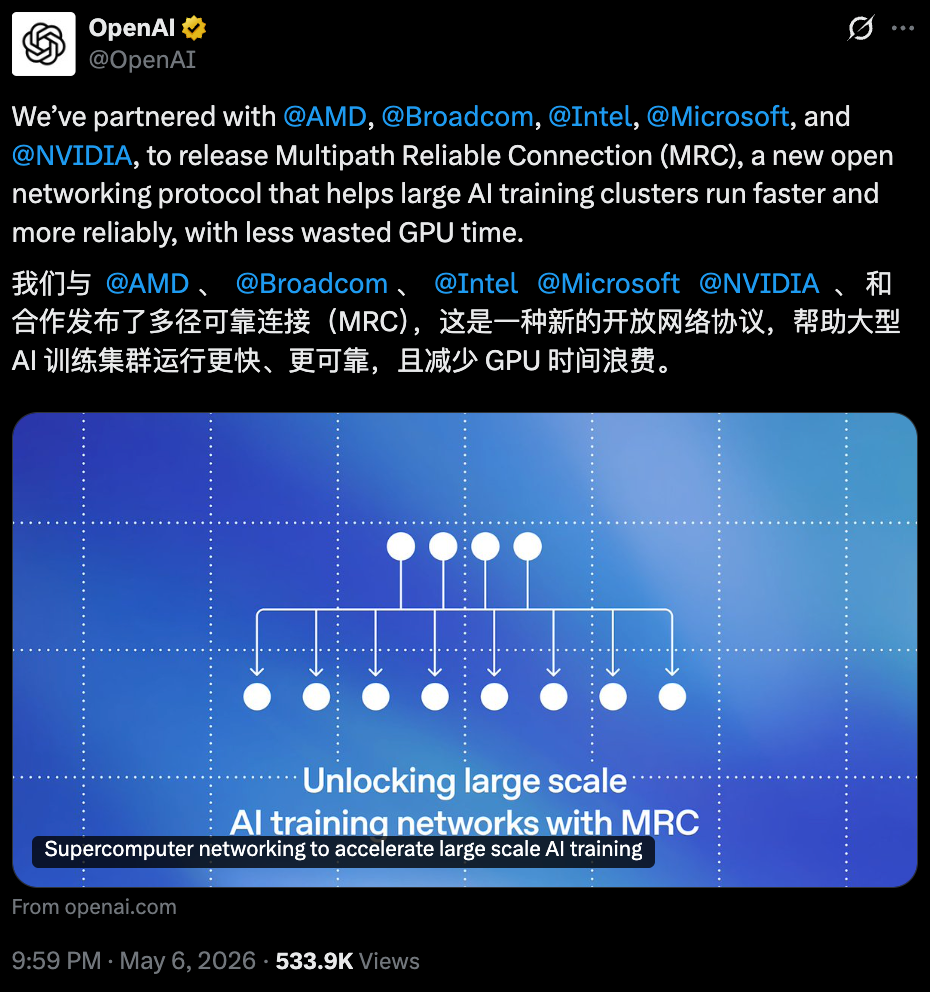
MRC采用了多平面网络,不再把每个网络接口视作一条800Gb/s的链路,而是将其拆分为多条更小粒度的子链路。例如,单个网络接口可同时连接八台不同交换机。由此便可搭建八路独立并行网络(网络平面),每路带宽为100Gb/s,而非构建单一的800Gb/s网络。
这样做的好处是,一台原本支持64个800Gb/s端口的交换机,改用后可提供512个100Gb/s端口,借此仅用两层交换机就能搭建出可全互联约 131000块GPU的网络;而传统800Gb/s组网则需要三层甚至四层交换机架构。
▲支持多平面网络
这样设计的网络成本、功耗都更低,且比传统网络设计能提供更多路径多样性的网络,还允许更多流量留在第0层交换机本地,从而提升性能。
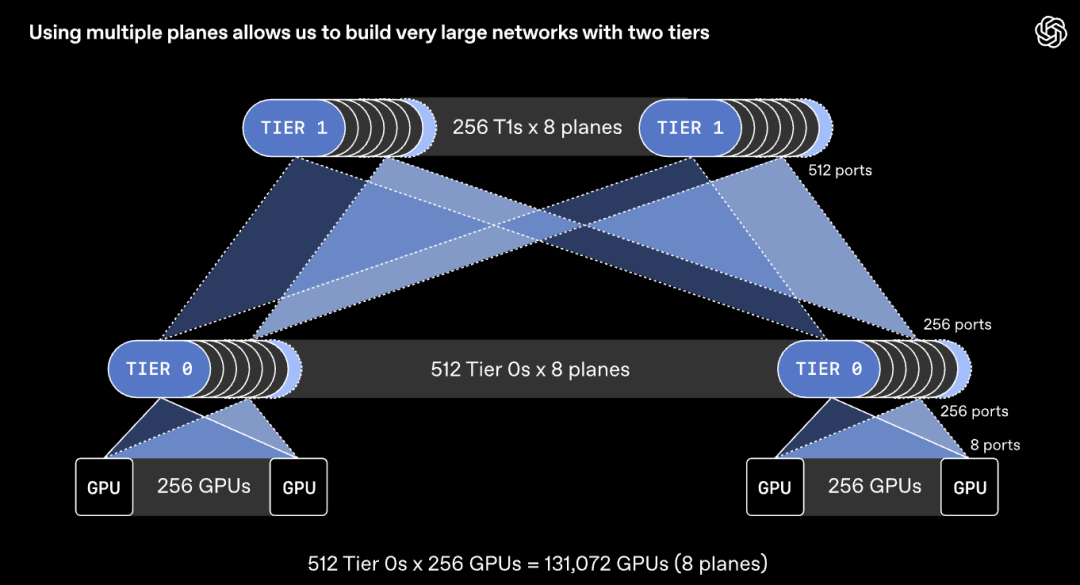
然而,这样的路径多样性往往难以被充分利用。用于AI训练的传统网络协议,通常要求每次数据传输固定走单一路径,以保证数据包按序到达。
在大规模多平面网络中,这会带来两大问题:一是不同数据流可能争抢同一条链路,引发网络拥塞;二是单条数据流只能占用众多网络平面中的其中一条。如果不做针对性优化,多平面网络反而会出现严重拥塞,整体性能表现会大打折扣。

▲数据包流相互碰撞导致拥塞
03.
跨数百条路径进行数据包散射转发
MRC从根本上改变了这一模式。
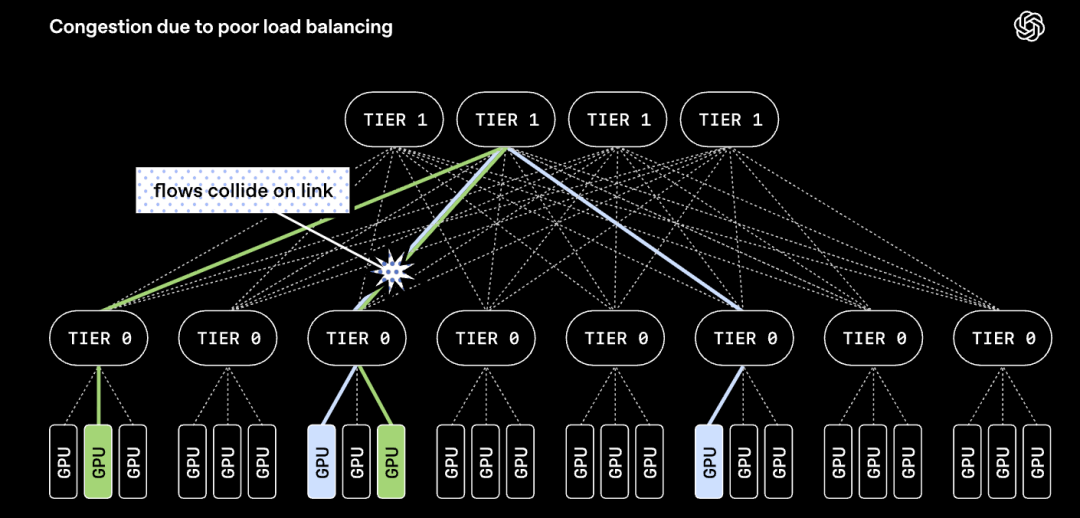
其不再将一次数据传输限定在单条路径上,而是把单次传输的数据包分散分发到网络中数百条路径、跨所有独立网络平面并行传输。
数据包可以乱序到达,但所有MRC数据包都携带最终内存地址,因此接收端无需等待排序,可随到随写入内存。
这样一来,每条MRC连接都会为其所使用的众多路径维护少量状态信息。一旦检测到某条路径出现拥塞,就会立刻切换至其他路径,从而均衡全网负载。

如果发生丢包,MRC会采取稳妥策略,默认该路径可能已出现故障,随即立即停用该路径,并对可能丢失的数据包进行重传。
在淘汰某条路径后,MRC会发送探测包核查是否确实存在故障;若确有故障,则进一步检测链路是否已经恢复。
还有一个丢包原因是目标端拥塞。MRC可以通过报文截断机制处理这类场景:当交换机因拥塞即将丢弃报文时,并不会直接整包丢弃,而是裁减掉有效载荷,仅将报文头部转发至目的端,以此触发显式重传请求。
并且报文截断能够有效减少误判,避免把单纯拥塞导致的丢包,错误判定为路径故障。
结合多平面拓扑、数据包散射转发、负载均衡与报文截断这些机制,MRC连接能够微秒级检测网络故障并完成迂回绕行,降低对同步训练任务的影响。相比之下,传统网络架构往往需要数秒甚至数十秒才能完成收敛稳定、实现故障绕行。
04.
进一步简化网络
一旦丢包即停止路径
MRC在简化网络方面更进一步。
传统方案中,交换机都会运行BGP(边界网关协议)这类动态路由协议,用以计算可用路径并实现故障迂回。
但交换机本身结构复杂、运行的软件也十分庞杂。一旦出现隐匿性异常,这类问题往往难以排查,还会持续引发连接中断,直至故障修复。
采用MRC后,一旦某条路径出现丢包,MRC便会停止使用该路径。
其采取的方案是,关闭动态路由,转而采用IPv6分段路由(SRv6)。SRv6允许发送端直接指定每个数据包在网络中的转发路径,实现方式是将交换机标识序列嵌入每个数据包的目的地址字段。
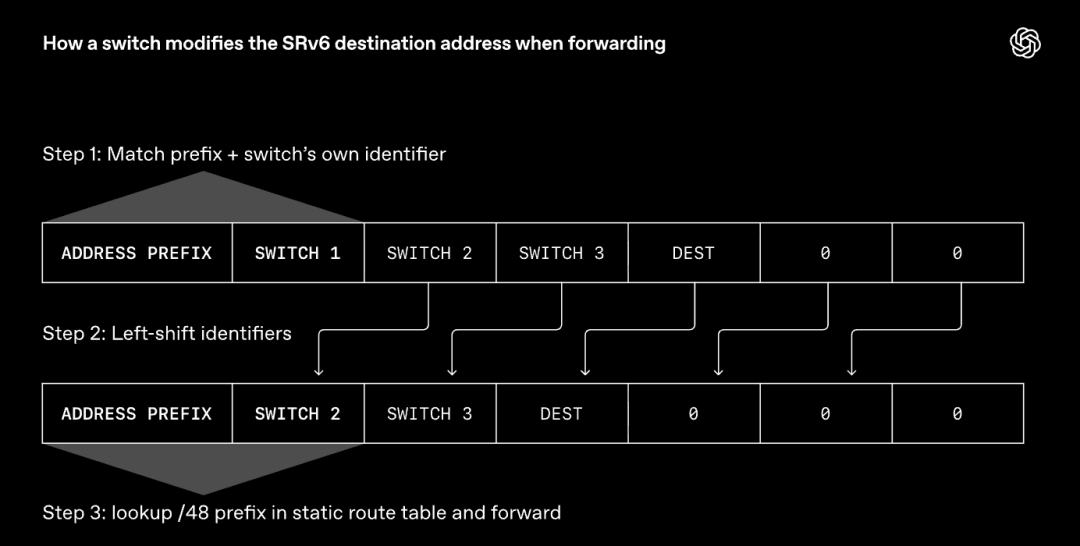
拆解原理如下:
交换机在转发报文时,会检查自身标识是否在路径列表中。如果命中,就通过偏移目的地址字段移除当前自身标识,露出下一跳交换机的标识。
随后交换机在静态路由表中查询该标识,据此决定报文的下一跳转发去向。
与动态路由不同,这类静态路由表在交换机初始配置阶段一次性部署完成,后续不再变更。
MRC利用SRv6在所有网络平面间分散分发数据包,同时在每个平面内并行使用多条路径。一旦某条路径发生故障,MRC直接停止选用该路径即可。
交换机无需重新计算路由,只需严格按照预设的静态路由规则进行转发,无需额外做任何复杂处理。
05.
结语:大厂联手
打破超算集群算力利用率瓶颈
根据官方博客,MRC显著提升了OpenAI训练全新大模型的能力,同时让网络架构能够匹配其AI发展路线图。
随着训练集群规模持续扩张,网络设计愈发决定可用算力的实际利用率。MRC能够让GPU集群在遭遇拥塞、链路故障和运维维护时保持协同稳定运行,而这类事件在过去都会中断训练任务。
在超大规模算力场景下,这种可靠性与运行效率或将成为支撑前沿大模型同步训练得以实现的基础前提。