
腾讯云数据库正在通过“DB For AI”和“AI in DB”两条腿,构建属于Agent时代的AI原生数据库。
文|游勇
编|周路平
数据库技术的演进有着一条相对清晰的脉络,过去十几年国产数据库的蓬勃发展大致可以划分为三个阶段。1.0时代,以腾讯云为代表的一批互联网厂商的数据库系统诞生,他们大多源于自身业务发展需要,从单机数据库转向分布式,成功扛住了互联网业务的高并发带来的数据洪峰,实现了国产数据库的高可用和高可靠。
到2.0时代,自主可控的需求紧随而来,国产替代成了业内的主导方向,大量关键基础设施和重点行业的核心系统开始进行国产替换。
如今,行业的指挥棒转向了AI Agent,数据库正式进入3.0时代。如何适应和满足AI Agent的需要,已经成为了全行业的课题。
就在上周,腾讯云数据库面向Agent场景进行了产品的全面升级,为Agent、AI编程和智能运维三大场景提供原生的AI数据库能力。当天,腾讯云不仅发布了Agent Memory、DatabaseClaw两款Agent原生产品,也对旗下最核心的云原生数据库TDSQL-C和分布式数据库TDSQL-B进行了系统性升级,全面适配AI原生。
01
Agent爆发,数据库面临多重挑战
数据库过去几十年的演进逻辑并没有发生太大改变,其本质是为人服务,比如控制台、注册流程、文档都是给人使用。但Agent依赖的是智能体之间的交互和工具的自主调用,数据库的用户从人变成了Agent,新的范式和业务需要改变了数据库的运行逻辑。
首先,多模态数据成为主流。过去,数据库处理的大量是订单、用户、交易记录等结构化信息,但AI的爆发,使得数据形态发生了巨大变化,“现在92%的新增数据都是非结构化”,比如会话状态、行业知识、上下文、图片视频等。
以前,单一模型的数据库会针对特定类型数据进行优化。比如订单、账户等结构化、强事务的数据,放在MySQL;半结构化、低延迟的数据放在MongoDB或Redis;非结构化的大文件放在对象存储。
这也意味着,多模态数据天然就散落在异构系统之间,而一旦需要跨系统融合分析,应用层的开发复杂度急剧攀升,非常割裂和痛苦。

“在一个复杂的企业级 AI Agent 应用架构中,我们会依赖和传统数据库迥然不同的能力。”腾讯云副总裁王义成说,比如查询不再仅仅基于关系模型,而需要向量和语义;数据不再仅仅是结构化,而可能是文本、图片。“这个时代真正需要的是多模存储和语义检索为原生的能力,并结合我们既有产品强项,例如高可用,支持SQL,高性能等,重新设计的产品。”
其次,是开发模式的转变。过去使用数据库,整体还是可预见的、访问模式也相对固定。而Agent的并发规模远超人工,对数据实时性也有更高的要求。尤其是当下,AI辅助编程让很多非专业人士也可以通过多轮对话创建Agent,越来越多AI应用开始直接访问数据库,带动了数据库实例的数量大幅上升,而且Agent多步骤任务又要求中间存档、随时回滚,传统备份恢复跟不上节奏。
“Agent是以人类无法比拟的速度去写代码、写用例、进行测试,跟团队做整体的组织协同,使得传统数据库的设计显得比较笨重,无法匹配。”王义成说。而Neon的数据也显示,2025年以来,由AI Agent创建的实例数量已经是开发者创建的4倍之多。
再者,数据库调用模式也在发生变化。过去的数据库偏离线分析,而Agent转向实时检索与持续性记忆。传统的解决方案遇到了很大的瓶颈,比如上下文窗口有长度限制和成本焦虑,RAG检索又丢失结构化推理路径,需要为Agent打造专属的记忆系统。
另外,随着Agent能力的增强和数据库治理复杂度的提升,Agent也在反过来协助DBA和研发人员更好地管理数据库,包括用自然语言做数据库的巡检、故障排查以及SQL优化。
02
DB For AI,为Agent重做数据底座
随着Agent在千行百业加速落地,业内也发现,Agent在真实场景的落地中最大的问题往往不是模型智商不够,而是容易出现记忆断片。
相比于过去问答型的人工智能,Agent这类复杂的长线任务,需要多步骤执行,需要调用各种工具和skill,非常考验记忆能力。比如系统不仅要听懂当下的指令,更要记得过去定下的代码规范、约束条件和推进节点。
不久前,Meta的AI对齐与安全总监就因为AI“指令遗忘”,导致其个人邮箱中200多封邮件被小龙虾批量删除。
针对Agent的记忆痛点,腾讯云数据库重磅推出了Agent Memory服务,重新为Agent打造了一套记忆系统。其核心是通过引入结构化与分层机制,对记忆进行统一管理。
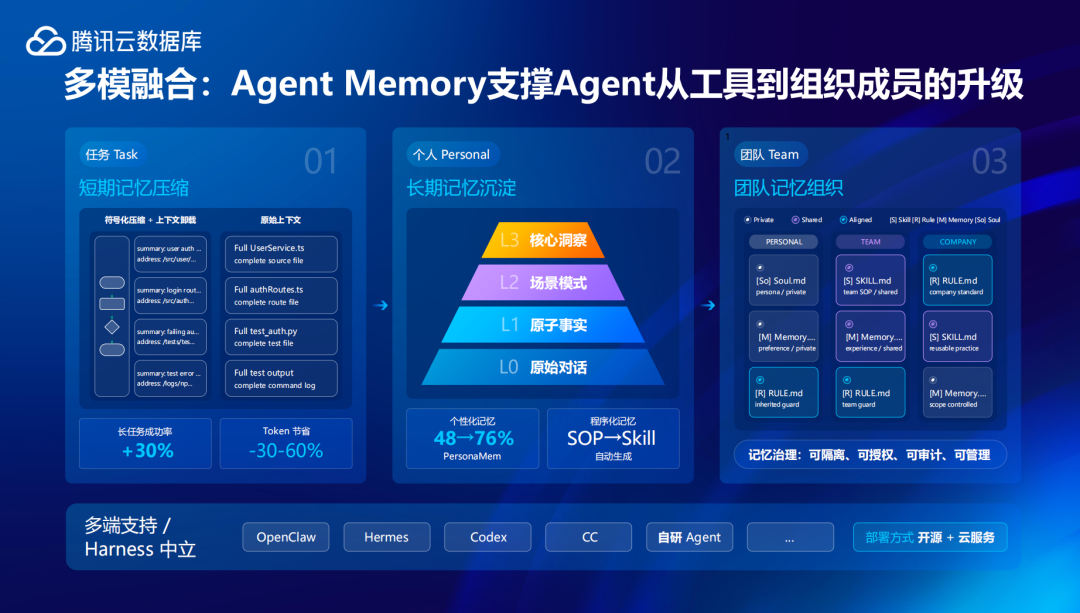
比如对短期记忆进行压缩,腾讯云数据库自研了符号化压缩和上下文的卸载能力。以符号化压缩为例,主要有两种思路:一种是摘要压缩,将繁琐的原始全文提炼为一行结构化的摘要,去掉废话,留下事实,提升单条信息的密度;另一种是结构化图压缩——用一张图替代一堆文字,让结构化的图来呈现不同操作背后的因果关系、状态,用最少符号承载最大语义。
而且,腾讯云数据库针对短期记忆设计了一套三级压缩策略,可以根据不同任务和负载,自动触发不同级别的处理。比如当上下文占比达到 60%时,自动用摘要替换原文,相对温和;而当上下文占比达到80%时,直接清理不再相关的旧任务消息,为当前任务腾出空间。
在长任务场景下,这套压缩机制不仅帮助Agent提升了30%的任务成功率,也让Token最高节省60%以上。“短期记忆我们做得比较领先,业界没有太多的方案。”腾讯云数据库副总经理罗成说。
针对长期记忆,腾讯云数据库也设计了从L0-L4的语义金字塔:其中L0包含原始的对话记录,L1是从对话中提取的原子化事实片段,L2是将原子事实组织成行为场景,L3则是从场景中归纳出用户画像、偏好、习惯用户。
借助这一机制,系统在执行过程中能够调用更稳定的关键信息,而不再依赖单一上下文,比如底层的原子事实只在需要核实细节时才按需检索。
甚至,腾讯云数据库在短期记忆和长期记忆之外,也在推动构建团队记忆。Agent在企业场景的应用往往依赖团队协作,这意味着企业级Agent需要能共享整体团队的上下文信息,理解同一套工作规则和标准,让多个Agent能像团队一样协作。不难发现,在Agent从个人工具转向组织协作的必然趋势下,腾讯云数据库已经开始从记忆层面帮助企业做着相应的数据准备。
而腾讯云数据库的Agent Memory已经对外开源,并且在开源社区受到了欢迎。上线两周时间,Agent Memory的开源代码就收获了近5K的Stars。
除了Agent Memory,AI也需要对会话的运行状态、行业信息等,进行长期的保存。
而每一种数据库都有各自的应用场景,比如结构化的业务数据用SQL查询,知识库语料又要用向量的召回,日志跟文档又要用全文搜索做关键词搜索。这也使得在企业的IT环境里,存在大量异构的数据库系统。
“Agent可能花了80%的时间在找数据,只有20%的时间在思考怎么用数据。“王义成说,Agent在执行任务时,要拿到一份完整新鲜的数据,往往需要穿越多套数据系统,应对不同数据库的延时,以及适配多种数据库的一致性协议。
针对这一痛点,腾讯云数据库发布了最新的TDSQL Boundless,这是一个面向AI时代的企业级多模态的数据存储底座。它支持一键纳管MySQL/PG、Mongo/Redis、COS、ES等数据源,让文本、图片、音视频等不同模态数据可以在同一个数据库内对齐。而且支持多模的计算,一次查询能同时调动语义、关键词、图谱、聚合四种能力,“这是任何单一数据库目前很难做到的”。
在存储架构上,TDSQL-B支持本地SSD、云硬盘和对象存储的多级存储云原生设计,存算分离,弹性按需扩展。数据规模从GB平滑增长到数十TB无需手动分库分表,冷热数据自动分层至对象存储,在保障高性能访问的同时大幅降低存储成本。
据悉,今年Q2,TDSQL Boundless将会重点推出面向向量索引和全文索引的应用场景,下半年则重点打磨基于对象存储原生和统一开放原数据服务的能力,而明年上半年会着重增强混合检索、融合检索,以及提供更完整的多模体验。
另外,针对AI Coding场景下数据库频繁复制、测试与回滚的新需求,腾讯云TDSQL-C也做了一次系统性升级,既支持MySQL也支持原生PG,可以一站式对接腾讯云cloudbase的baas平台以及Cursor、FastGPT等这些AI 开发者应用,用MCP、REST等协议统一接入。
这一次的升级核心是引入数据库Branch能力,让1TB数据库从过去小时级复制压缩至秒级“分叉”;叠加Serverless秒级启动、闲时归零的能力,更贴合 AI 编程“高频创建、低频使用”的长尾负载;提供AI Toolkit工具箱,实现了亿级向量零损召回、列存实时分析提速10倍、向量检索内存再降75%——RAG、长期记忆、实时洞察这些复杂AI需求,开发者不用再东拼西凑,一库直达。
此外,TDSQL-C为了更好适配Agent应用,重构了新一代存储架构,通过重写日志系统、写入路径和读取路径彻底解耦;引入多数派写入协议,构建地域级全对等架构,告别木桶效应;原生支持行列混存,同一份数据、同一套日志、同一份事务一致性——TP/AP不再需要两套库两条链路;冷数据再下沉到对象存储COS,备份快照和无限容量都顺手解决。最终带来的效果是:极致性价比,TCO较同类产品下降200%+;IO零抖动、全链路无损变更;数据零丢失,3 AZ金融级强同步、RPO=0。
03
AI in DB,给数据库装一只龙虾
数据库领域对于AI的实践,普遍有两条路线。其中一条就是上述提到的DB for AI,让数据库更好地去满足Agent的运行需要;另一条则是AI in DB,将Agent引入数据库的运维和治理流程中,让Agent帮助研发或者DBA做数据库巡检、故障排查以及SQL优化等工作。
这背后,是数据库的运维正在遭遇一场不对称的战争。
DBA紧缺已经是行业性难题,即便是在大型企业也是如此,而数据库的分类非常复杂,这也增加了DBA的运维难度。甚至vibe coding的流行,让很多非研发岗位的人也在大量创建数据库实例。在如此内外交困的情况下,用Agent来进行数据库的智能运维就成了刚需。
小红书就是一个典型案例。业务的高速成长使得小红书的数据规模迅速膨胀,而支撑业务的所有数据库产品集群规模都在翻倍扩张,给后台负责运维的人员带来巨大压力。“传统靠人肉、靠SOP、靠加人扛的路子基本上走到尽头了。”小红书数据库DevOps专家许嘉正说。
作为腾讯云首个数据库Agent,DatabaseClaw可以做到一句话巡检,并且生成结构化的巡检报告,而且不管底下跑的是MySQL、Redis还是MongoDB,AI自动识别引擎,加载对应的诊断策略。它可以逐条解析执行计划,告诉你哪些需要建索引、哪些需要改写、哪些其实不用管。

但理想与现实之间依然还存在鸿沟。比如Agent对线上SQL慢查能分析得头头是道,但很多业务人员并不敢直接将AI的建议用于真实的生产环境。因为通用的AI没有上下文,没有调用内部的工具链,也没有风险边际和证据链的意识,往往只是单纯根据SQL文本做了形式化的分析。
与通用智能体不同的是,腾讯云DatabaseClaw基于过去十几年服务客户积累的十几万工单,将SOP流程沉淀为Skills,相当于让Agent在执行各种任务时都有一套最佳用户实践。比如当数据库出现慢SQL的问题,通用Agent往往会给出一个似是而非的建议,而DataBaseClaw会多做一步,先找到慢SQL产生的具体原因,然后对症下药。
“DataBaseClaw能够相比较之前一个人干的活能够有十几倍效率的提升。”罗云说。
除了把专家经验炼化为可以直接调用的Skills,DataBaseClaw也实现了多引擎的统一纳管。不同类型的数据库有自己的特性和运维工具,比如MySQL要看缓冲池命中率,Redis要盯内存碎片,MongoDB要查慢操作。而DatabaseClaw用单一的Agent实现了MySQL、Redis、MongoDB、TDSQL四大主流引擎的原生覆盖,DBA通过自然语言就可以查询数据的状态、生成报表,降低整体使用门槛。
相比于提高效率和易用性,安全可控是企业敢于将Agent用于真实生产环境的最关键一环。
不久前,一位SaaS企业创始人就发帖称,他在使用智能体执行测试任务时,由于凭据不匹配,Agent竟自主搜索代码库找到一个无关的 API Token,把整个生产数据库给删除了。现实中,数据库关系到企业业务的稳定,很多企业不敢将Agent用于真实的生产环境中,一些不合规范的操作可能对系统造成不可逆的损害。
而DataBaseClaw则从三个层面提高Agent的安全防护。一是设立行为护栏,相比于简单通过Prompt工程对龙虾进行限制,DataBaseClaw用了规则化或者持续化的方式在上层对龙虾进行限制,比如只读权限和分析权限分离,一些变更类的操作需要用户二次确认。二是让龙虾的操作环境白盒化,DataBaseClaw部署在用户可见的环境上,龙虾安装了什么Skills,配置了什么策略,用户完全可知。三是全链路进行审计,关键的信息脱敏,整个链路只保留做什么了,为什么要做。
不难发现,DataBaseClaw通过融入人类专家经验、设立安全护栏等方式,本质上是解决的是通用Agent目前能力边界有限和安全风险失控的难题,帮助客户真正敢于将Agent用于数据库的真实运维环境中。
结 语
Agent带来了全新的数据使用方式和复杂多元的数据形态,又给底层的数据库带来了巨大的机遇和挑战。数据库的价值在AI时代没有被削弱,反而在增强。如何为Agent的高效运行打造一个AI原生数据库,正在成为数据库厂商们集体探索的方向。
在这条迈向AI原生数据库的路上,腾讯云基于全栈自研的数据库底座,围绕DB For AI和AI in DB的双重布局,已经构建了从AI应用开发到运维运行的完整链路。
模型决定了Agent的下限,而记忆决定了Agent的上限。在模型能力放缓、系统工程备受重视的当下,AI原生数据库就是腾讯在Agent时代给出的最佳答案。