
不到一个礼拜,接连两位重量级员工都离开了谷歌。
前有Google DeepMind工程副总裁诺姆·沙泽尔(Noam Shazeer),后有AlphaFold核心负责人约翰·江珀(John Jumper)。
讲真的,我很难不怀疑谷歌现在“出BUG”了。
从Gemini 3问世,到现在都过去大半年了,谷歌还是只有差别不大的Gemini 3.1。你再看看Anthropic这边,半年前还只是Opus 4.5,现在Fable 5都停用一个多礼拜了。
不只是模型掉队,产品也跟着掉队。如今几乎所有的AI公司都在发力AI Agent,OpenAI有Codex,Anthropic有Claude Code。
Fable 5加持下的Claude Code,现在都能自主修bug,自动循环跑测试直到全绿,还能从设计稿直接生成生产代码,最后封装成完整的软件。
而谷歌这边,只有一个拿不出手的Antigravity 2.0,不仅效果糟糕,使用体验也一言难尽,网上对这个产品只有一片骂声。
说到这里就不得不提一件事,伯克希尔从2025年就开始建仓谷歌,到了2026年第一季度,伯克希尔把谷歌的持仓又加了224%。
2026年6月1日,伯克希尔以定向增发的方式向谷歌母公司Alphabet再投了100亿美元。
难道这回巴菲特真的看走眼了?

谷歌的全栈优势怎么没了?
2025年11月18日,谷歌发布了Gemini 3。皮查伊亲自出来站台,说这是谷歌“最智能的模型”,拥有全球最顶尖的推理能力,多模态理解,还有代码生成能力。
于是在同一天,谷歌还放出了另外两样东西:一个是Google Antigravity,号称“agent-first”的开发平台;一个是Nano Banana Pro,它是谷歌此前爆火的文生图模型Nano Banana的威力加强版。
当时的谷歌有多吓人?这么说吧,在谷歌这场产品发布会结束后两个礼拜,奥特曼向OpenAI内部发出“Code Red(红色警报)”备忘录,称ChatGPT的产品体验与质量优势正在被谷歌快速追近,因此全公司暂停所有其他业务,集结全员投入到ChatGPT当中。
奥特曼担心的不只是这三个产品,而是谷歌的全栈优势。
在硬件上,谷歌有自研的TPU芯片。谷歌从2015年就开始做TPU,到今天已经到了第七代Ironwood,一颗芯片顶过去四颗的算力,液冷散热,一个pod塞进去9216颗芯片,提供42.5 ExaFlops的算力。
和英伟达那种通用的GPU不同,TPU是专门为AI推理任务进行过优化的,成本低,而且性能更好。
再往上一层是DeepMind。
2023年4月,谷歌把Google Brain和DeepMind合并成了一个单位。此前,这两家虽然是同一家公司,但长期以来是两套体系、两套文化,Brain偏产品和商业化,DeepMind偏长期研究。
合并之后,哈萨比斯统一带队,杰夫·迪恩(Jeff Dean)退居首席科学家。也就是说,谷歌的“左右脑”合一了。
继续往上,还有一层很多人容易忽略的东西:入口。谷歌不是只有模型,它有Chrome、Android、YouTube、Google Maps、Gmail、Google Workspace、Google Search。
这些东西加起来,日活几十亿。全世界没有任何一家AI公司拥有这个量级的用户。它能通过入口去铺产品,再用这些成熟的产品拿到用户反馈,加快整个产品的开发迭代。
比如用户在哪一步退出了,哪种能力被反复调用,哪些生成结果被用户改掉了或者直接放弃了,哪些功能形成了留存,哪些场景出现大量报错和投诉。

就拿Nano Banana来说。
这个产品虽然体量非常小,但是它其实是通过谷歌的全栈,拥有自己一个完整飞轮。
Nano Banana刚刚在LM Arena一类的盲测环境里走红后,谷歌做的第一件事就是把它立刻上线到Gemini App、AI Studio、Gemini API当中,甚至连专门面向企业的Vertex AI也没放过。
用户不仅能通过各种产品感受Nano Banana,谷歌还能用这些产品收集反馈,这也就是为什么Nano Banana产品迭代速度那么快,碾压GPT-4o的作图能力。
那为什么到现在,谷歌的全栈优势没了呢?
文生图是一个低风险、短链路、结果立刻可见的产品。
用户输入一句话,几十秒后得到一张图,不满意就重来,满意就分享。它不需要长期记忆,也不需要调用工具权限,更不需要为一次错误承担现实后果。
但是Agent不一样。它不是“给用户一个结果”,它是要彻底驻扎进用户的工作环境,持续读取上下文、调用工具、执行操作,并对最后的结果负责。
Nano Banana的成功并不能完全复刻到Agent了。
当产品需要跨模型、权限、执行环境、企业系统和长期责任时,谷歌那套原本强大的全栈能力,开始显露出协调不起来的问题。

谷歌真正的病是组织架构太混乱
如果你去翻谷歌的开发者产品线,你会发现一个很诡异的现象。谷歌同时有好几个工具,都在帮你用AI写代码,产品功能几乎都重叠了。
Gemini CLI,一个命令行工具,可以查代码库、生成应用、自动执行复杂流程,2025年底随Gemini 3一起推出。到了2026年6月,谷歌发了个公告:Gemini CLI即将被Antigravity CLI取代。
Jules,一个异步编码Agent,Google Labs出品,定位是自动帮你修bug、写测试、提Pull Request。它不需要你盯着看,你把任务扔给它,它自己克隆仓库、写代码、开PR,干完了通知你。
Code Assist,Google Cloud旗下的企业级编程助手,装在VS Code和JetBrains里用,收费22.8到54美元一个用户一个月。Firebase Studio,浏览器里的全栈开发工作台,内置了Gemini,也能帮你生成代码。
然后是永远扶不上墙的Antigravity,前文也提到了,2026年5月I/O大会上又发了个2.0版本,分了桌面App、CLI、SDK、Managed Agents、企业层五块。
它们都在做同一件,但它们是不同团队做的,有不同的品牌名,有不同的入口,有不同的收费模式,甚至有的在互相替代。
这种情况根本就不叫产品线丰富,这叫浪费算力。
这件事的根源其实是在组织架构层面。
谷歌的AI Agent相关能力,被拆分在至少几个互不统属的组织手里。每个组织有自己的KPI,独立的汇报线。
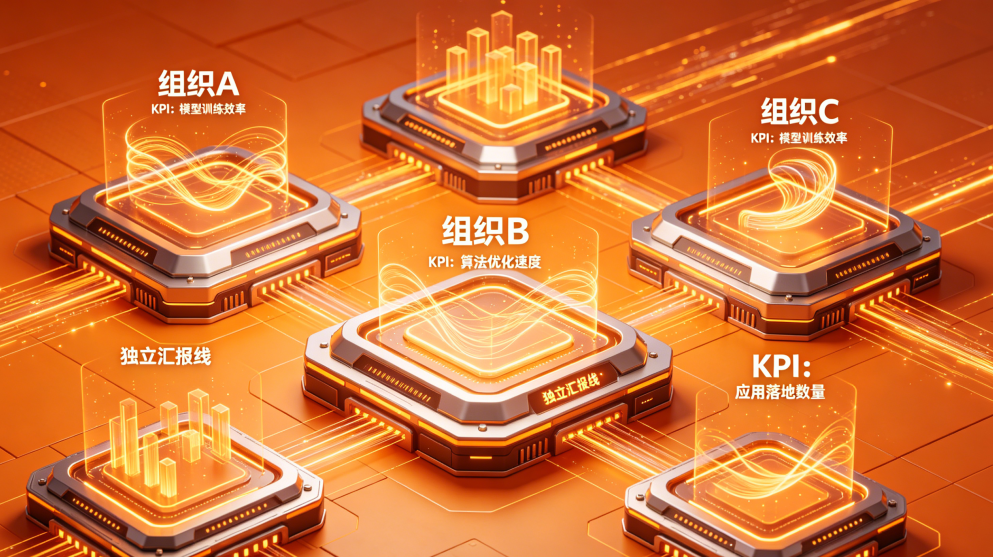
比如Google DeepMind,它管的是模型在benchmark上的分数能不能压过GPT和Claude。DeepMind的成功是“我们做出了最强的模型”。
它根本不关心用户在Antigravity里完成一个真实项目的成功率是多少。
到了Google Labs部门,它只管这个东西酷不酷,能不能在社交媒体上引发讨论。
Google Labs的产品有CC(Gmail里的AI助理)、Project Genie(无限世界生成)、Pomelli(AI营销工具)、Opal(自然语言做小应用),以及Jules。
实验跑完了,热度过去了,团队可能去做下一个实验了,它不会对产品进行长期维护。
Google Cloud和Vertex AI管的是模型能不能通过API调用,企业能不能采购,权限和合规有没有覆盖,Agent能不能部署到生产环境。
Antigravity更惨,它是从Google DeepMind里面走出来的,现在归Google Labs维护。但是又必须接入Google Cloud的权限、部署和合规体系。
所以谁也不会对它负责,就这么摆烂。
你可能会问了,那到皮查伊这关可怎么办?
DeepMind说,我们的模型又刷榜了。Labs说,Jules在社交网络上又有10万转发了。然后Google Cloud那边说,Agent Engine又签了多少个企业客户。Gemini App说,这个月的DAU稳住了。Search说,AI Overviews用户破20亿。
大家的饭碗都保住了,却最后留给Antigravity一地鸡毛。
但没有人能回答一个最简单的问题:一个开发者,今天应该用谷歌的哪一个工具来完成他的工作?如果他现在用的是Codex或者Claude Code,谷歌准备用哪个产品把他抢过来?

评测赢了,不等于任务真的交付了
谷歌现在所有的叙事都只围绕着评分,但现在大家早就不迷信benchmark了,能交付任务的才是好模型。
模型在benchmark上分数高,比如它推理题能答对,代码能生成,图像能看懂,多轮对话能保持连贯。
这些测试通常是在受控环境下进行的。单轮或有限轮次,输入输出干净,不需要操作外部工具,不需要管理权限,不需要长时间持续运行。
失败了的表现是什么?答案不对。最坏的结果,就是重来一遍。
但是到了任务交付这块,模型的价值变了。
用户把一个真实的工作扔给AI,到最后拿到了一个能用的结果,中间的链条其实是非常长的。
什么叫“真实的工作”?是“这个项目的支付模块有个bug,请定位、修复、测试、提交PR”。它涉及多个步骤,可能要花几十分钟甚至几个小时,中间需要调用Git、终端、浏览器、文件系统、API,每一步都有失败的可能。
失败了的表现是什么?不是答案不对,而是代码改坏了、权限控不住了、流程卡死了、环境崩了、用户不知道从哪里恢复。
我举个例子。
假设一个模型在单步判断上的正确率已经有95%,看起来很强;但一个真实开发任务若需要连续完成20个关键步骤,全部不出错的概率只有0.95^20,约等于36%。
哪怕单步正确率提升到98%,20步全程顺利完成的概率也只有约67%。
所以Agent产品真正的护城河,不是把benchmark再刷高两分,而是给错误恢复、状态保存、权限确认、人工接管、回滚和结果验证做出可靠机制。

但是Antigravity都2.0了,还是没有类似且完整的机制。
你去读Gemini 3的官方博文,皮查伊亲自写的开头,后面跟着的全是benchmark对比表。
但是你现在如果去看OpenAI和Anthropic关于新模型的官方博文,里面全都是各种客户对模型的评价。
不是说benchmark没用。benchmark当然有用,它是一个尺子。但如果一个Agent产品的全部叙事都围绕benchmark展开,那就说明这个模型确实干不了活。
谷歌不可能放弃AI Agent,因为这个板块真的太赚钱了,不信你看看友商们就懂了。
2026年2月,OpenAI的Codex,独立桌面App上线后首周下载量超过100万。仅仅过了两个月,Codex周活用户就达到了400万
Claude Code就更不用说了,Anthropic在2月份的融资材料中就暗示,该产品的年化收入已经突破了20亿美元。
Antigravity 2.0发了一个多月了,现在打开它的官网,你会发现还是没有企业版的定价。
Claude Code可以通过Claude Team按人头付费,Codex可以走GPT Business或者ChatGPT Enterprise,同样是按人头收费。
到了谷歌这里,企业要是想用Antigravity 2.0,你只能走Gemini Enterprise Agent,它会赠送你一些额度让你拿手上玩玩,并不能像OpenAI和Anthropic那样,把它变成一个收费的产品。
所以我猜沙泽尔和江珀离开谷歌,大概也是因为对这家公司失望了。

欢迎在评论区留言~
如需开白请加小编微信:dongfangmark





