(本文作者为 AI唱反调,钛媒体经授权发布)
文 | AI唱反调
阿里、 Momenta、英伟达最近都在讲"世界模型"。阿里那个能让 AI 帮你操作电脑,Momenta 那个能让车预判路人下一步,英伟达那个能生成逼真的暴雨视频。如果不太关注技术细节,大概率会以为这是同一个方向的三次突破,像同一个班里的三个学霸同时考了满分。
真相很直接:这三样东西除了名字一样,几乎没有任何关系。把它们统称为"世界模型",就像把"世界地图""世界时钟"和"世界观"当成同一类东西。字面上都有"世界",实际各说各话。
阿里做的是让AI 在电脑里先试错的"数字沙盘",Momenta 做的是让自动驾驶预判路况的"老司机直觉",英伟达做的是给 AI 造训练素材的"虚拟片场"。三个"世界",三条平行线,谁也不挨着谁。
同名不同命
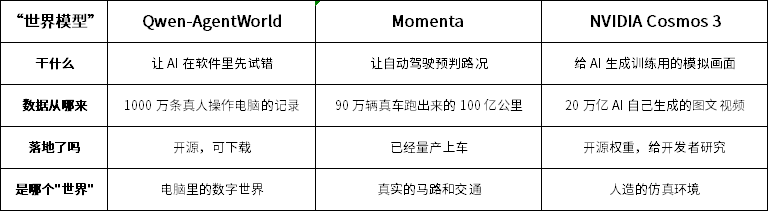
第一个是阿里Qwen-AgentWorld,本质上是一个给 AI 用的"数字沙盘"。
它把浏览器、电脑桌面、手机界面、代码编辑器这些环境打包成一个虚拟游乐场,让AI 在里面先试错、再行动。比如操作某个软件会不会点错按钮,先在沙盘里预演一遍,成功了再去操作真实的电脑。这基于超过 1000 万条真人操作电脑的记录训练。AI 看了上千万次真人怎么写代码、怎么搜索、怎么填表格,学会了"点这里之后通常会发生什么"。
它的"世界"是电脑里的数字空间:网页、App、代码仓库。和真实的马路、真实的机器人没有直接关系。
第二个是Momenta,那套已经量产上车的系统,它是自动驾驶的"预判本能"。
自动驾驶最大的难点已经变了。现在的问题不再是"看清前面有什么",变成猜出下一秒会发生什么。前车突然减速,是要靠边停车还是临时踩了一脚?路边行人是要过马路还是等公交?Momenta 就是让 AI 提前在脑子里过一遍未来几秒的交通画面,然后选最安全的动作。这背后不只是直觉,还涉及感知、预测、规划多个模块的协同。
关键是,这东西已经量产了。Momenta 有 90 万辆车在跑,积累了 100 亿公里的真实驾驶数据。这些视频不只是"看着玩",里面包含"当时做了什么、车怎么反应、结果对不对"的完整因果链条。它的"世界"是真实的物理世界:马路、车辆、行人、雨雪天气。
第三个是NVIDIA Cosmos 3,它是给 AI 造训练素材的"虚拟片场"。
它的核心能力是生成逼真的视频画面,但这些视频不是拿来刷的,是给机器人和自动驾驶当练习题用的。比如想让AI 学会"暴雨天路面反光看不清车道线"怎么处理,现实中不可能天天等暴雨,Cosmos 3 就生成一段暴雨开车的视频,让 AI 在虚拟画面里反复练。
它开源了权重,能处理文字、图片、视频、声音、动作指令五种信息,20 万亿 token(token 是 AI 处理信息的最小单元,文字、图像、视频、声音都会被切成这种"小块"喂进去)说明它看过、生成过巨量素材。但关键是,这些画面属于"合成数据",AI 自己造的,不是真实拍摄的。好处是成本低、场景全;坏处是"仿真"和"真实"之间永远有差距。
它的"世界"是人造出来的仿真环境,本身不直接开车,也不直接操作电脑,只给其他 AI 提供练习题。
世界模型:一个被掏空的标签
其实"世界模型"定义混乱这件事,学界自己也头疼。今年 6 月初,李飞飞团队在 MIT Technology Review 发文,标题就叫《当视频生成、机器人和 NVIDIA 都自称世界模型》。文章里提到,Sora 被叫世界模拟器,Genie 被叫世界模型,现在连做自动驾驶的、做机器人的都在用同一个词。
6 月中旬的智源大会上,智源研究院院长王仲远干脆把世界模型分成了四大类:以语言为中心的、以像素为中心的、以三维结构为中心的、以视觉表征为轴心的。看,连顶尖研究者都没法统一口径。
那三者的共性到底是什么?它们都在做"预测"或"模拟"。预测点一下鼠标会发生什么,预测前车减速后下一秒的路况,预测暴雨天的路面长什么样。但预测的对象完全不同:一个在预测数字环境里的操作后果,一个在预测物理世界里的交通演变,一个在预测仿真画面里的场景参数。
这就好比"预测"这个词,可以预测股票、预测天气、预测孩子考多少分,都是预测,但干的事完全不同。世界模型现在就是这个状态:同一个词,被用来描述三种完全不同的能力。
闭环定生死
这三个"世界模型"不会合并成同一个东西,未来会沿着三条线走。

第一条是数字世界模型,解决"AI 怎么操作软件、怎么写代码"的问题。由 Qwen、OpenAI、Claude 这类公司主导。特点是迭代快、数据成本低,因为电脑里的操作记录很容易获取。和我们关系最近:以后用的 AI 助手,可能先在后台沙盘推演一遍,再帮忙订机票、填表格。
第二条是物理世界模型,解决"自动驾驶怎么安全开车、机器人怎么搬东西"的问题。由 Momenta、Tesla、华为这类公司主导。特点是数据成本极高,需要真车去跑,但一旦形成闭环,壁垒极深。和我们关系:以后坐的车、看到的无人配送车,背后都是这类模型。
第三条是基础设施线,NVIDIA 的角色更像一个"卖铲子的"。Cosmos 3 提供合成数据,让上面两条线的开发者都能用,但它自己不直接开车,也不直接操作电脑。它赚的是"造影视基地"的钱,不是"拍戏"的钱。
判断谁更领先,别只看参数大不大、开源不开源。真正重要的指标是闭环,AI 在真实环境里用了之后,能不能把结果反馈回来,让自己变得更聪明。
Momenta 的闭环最扎实。90 万辆车每天在路上跑,AI 预测错了,数据就会回来告诉它"下次别这么猜"。这种真实世界反馈是合成数据替代不了的。
Qwen 的闭环在数字世界。1000 万条真人操作的成功和失败经验被记录下来,成了 AI 的教材。在"让 AI 操作软件"这个赛道上,这是稀缺资产。
Cosmos 3 的闭环在仿真基地内部其实很高。它生成视频、测试、反馈、再生成的循环在虚拟环境里跑得很快。但要把这些画面喂给真实世界的汽车或机器人,还要跨一道"从仿真到现实"的鸿沟。这一步目前还没完全打通。
三者的区别很明显:Momenta 是在真刀实枪开车中进化,Qwen 是在真人操作电脑中进化,NVIDIA 是在人造影视基地里进化。没有高下之分,只是战场不同。
下次看到"世界模型"四个字,先问一句:说的是电脑里的、马路上的,还是人造影视基地里的?答案不同,选择完全不同。现在喊"世界模型"的,一半是真在做,一半是借这个词给自己贴金。分得清前者后者,才不会被 PR 稿带跑偏。